只需1/4预算,性能反超基线:阿里高德提出Tree-GRPO,高效破解智能体RL难题
对于大模型的强化学习已在数学推理、代码生成等静态任务中展现出不俗实力,而在需要与开放世界交互的智能体任务中,仍面临「两朵乌云」:高昂的 Rollout 预算(成千上万的 Token 与高成本的工具调用)和极其稀疏的「只看结果」的奖励信号。
来自阿里高德的一篇最新研究论文提出了面向 Agent RL 的 Tree-GRPO 方法,将独立的链式采样改造为智能体步骤级的树搜索。该方法通过共享前缀、一次扩展多个分支,在相同预算下获得更丰富的有效轨迹;更重要的是,仅凭最终奖励即可沿树结构回溯出过程中的偏好信号,等价于隐式的步骤级偏好学习。
在 11 个知识密集型、网络搜索问答任务数据集中,Tree-GRPO 在多种模型规模上更省预算、更高表现,显著优于链式 RL 方法,甚至能在 1/4 预算的情况下超越 GRPO 基线,为 Agentic RL 的高效训练提供了新的解决思路。

论文标题:Tree Search for LLM Agent Reinforcement Learning
论文地址:https://arxiv.org/abs/2509.21240
代码链接:https://github.com/AMAP-ML/Tree-GRPO
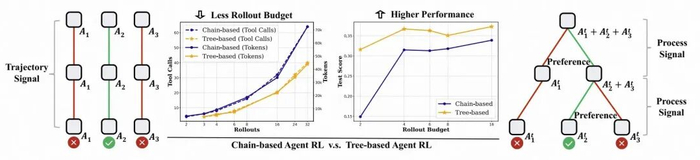
树方法相较链方法的区别与优势
Agentic RL 的痛点

(左)链采样,(中)token/sentence-level 树采样,(右)agent-level 树采样
在 Agentic RL 中,LLM 不再是被动的文本生成器,而是一个在动态环境中的自主决策智能体。在 ReAct 视角下,LLM Agent 的决策轨迹由一段连续的多步行动构成,在每一步中,智能体都会进行思考(Think)、行动(Action)、观察(Observation)三个行为。
这样的开放式多轮轨迹在 RL 中面临两点关键瓶颈:
Rollout 采样成本高:多回合交互的轨迹中包含成千上万 Token 和多次 tool-calls。现有链式采样为同一任务反复生成多跳独立轨迹,采样冗余高,训练时间几乎被 rollout 吞噬,且外部工具(如搜索 API)费用不菲;
多轮长轨迹的监督稀疏:绝大多数方法仅能依赖最终奖励评估整条轨迹好坏,难以定位「哪一步/哪一次行动」贡献了成败,导致在预算增长时有效训练信号并未同比增加,学习过程失衡甚至出现训练崩溃。
Tree-GRPO:
以「智能体步骤」为节点进行树搜索
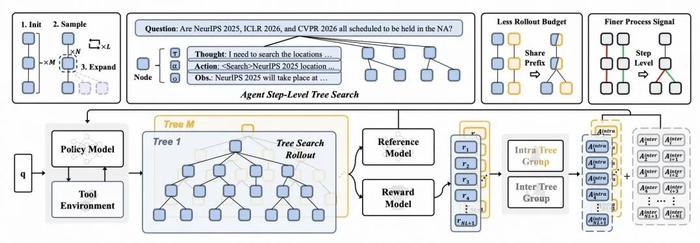
Tree-GRPO 训练总览,左上为采样流程,右上为两个主要优势,下方为训练流程
已有的树搜索 RL 方法通常在 Token 级或句式级别上进行,对于有明确步骤级语义结构的智能体来说并不适合。该团队提出以「智能体步骤」为树节点单位的树搜索,即每个树节点对应一个完整的思考、行动、观察步骤。为适配现有 LLM 并行推理框架,我们采用「先初始化—后扩张」的策略:
初始化 M 条独立轨迹;
每条轨迹随机采样 N 个节点,以根节点到采样节点作为完整上下文进行扩张;
通过重复步骤 2 L 次,最终获得分散在 M 棵树的反应轨迹。这样的树搜索能够在一定的 rollout 预算下获得更多的 Agent 轨迹。
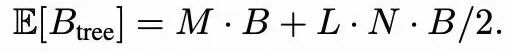
基于树的优势计算
通过树结构的样本轨迹,该方法还能够在仅凭结果奖励下构造出 step-level 的偏好目标,形式与离线构造 DPO 数据优化目标一致。
对每棵树而言,在每个分支节点,从叶节点回溯得到的奖励差值天然形成一个偏好优化目标,而兄弟子树的深度决定了该过程信号的粒度。
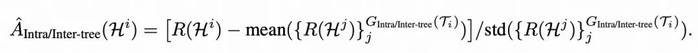
为进一步提升 RL 训练中优势估计的稳定性,避免因单棵树轨迹数量过少导致的偏差或方差,Tree-GRPO 还对所有树间的轨迹优势进行归一化,并将归一化结果与原始优势相加,作为最终的优势估计。
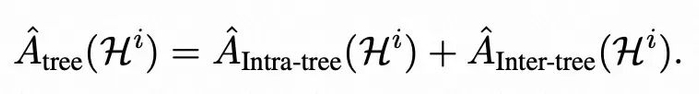
最终的优化目标为:
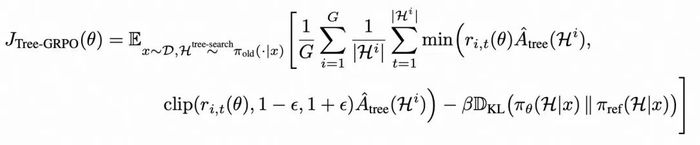
值得注意的是,这样的树内 GRPO 在梯度形式上和 step-level DPO 的优化目标保持一致
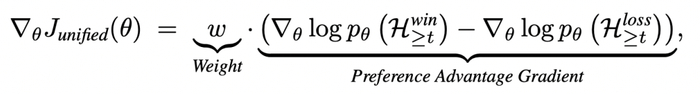
实验结果:
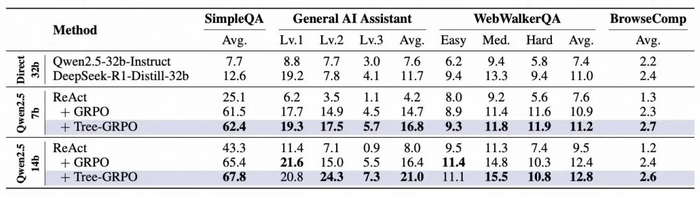
11 个 Agent 问答任务评测
本文在包括 Llama3.2 和 Qwen2.5 系列的多个参数规模模型上进行了评测。实验结果表明,Tree-GRPO 在所有任务上均稳定优于链式 RL 方法,其中多跳问答(QA)性能提升尤为显著:在较小模型 Qwen2.5-1.5b 上有 69% 相对提升,在 Qwen2.5-3b 上取得了 36.8 的平均 EM 得分。
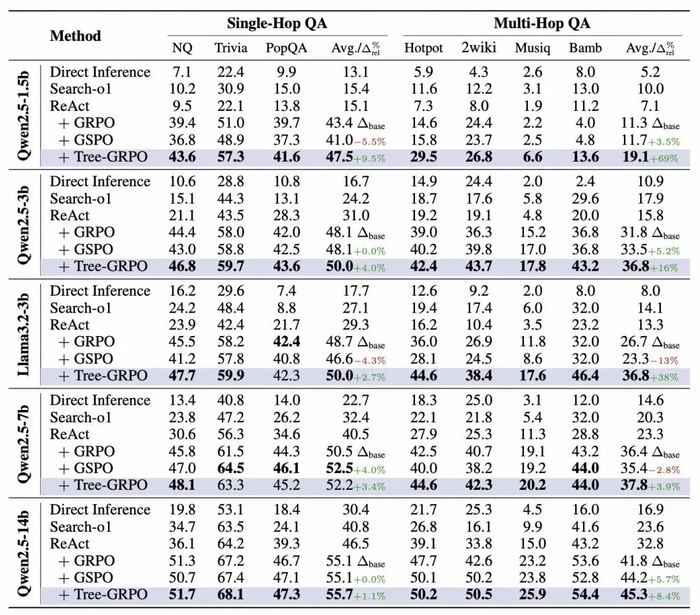
在 Web-Agent QA 实验设定中,Tree-GRPO 在各项指标上也均有稳定提升,在 GAIA 中有相对 28% 性能提升。
进一步分析:
树搜索 RL 的更多优势
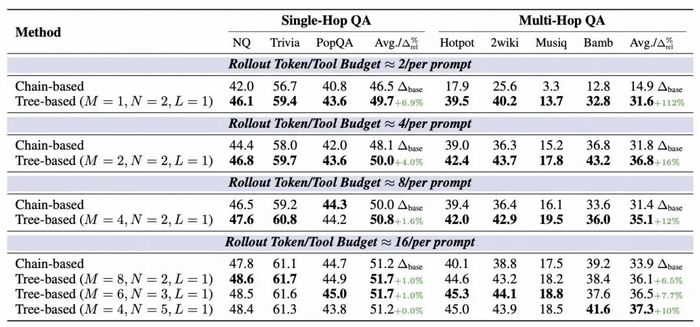
由于 Rollout 预算是 Agentic RL 中一个重要限制,本文在不同预算设定下进行了实验,结果表明 Tree-based 方法在各种设定中均稳定优于 Chain-based 方法,尤其是在预算极其受限情况下(每个 prompt 仅 2 条完整轨迹),Tree-GRPO 相较 Chain-based 方法有 112% 提升;另外,该方法能够在 1/4 预算情况下获得更优性能(36.8 vs 33.9)。
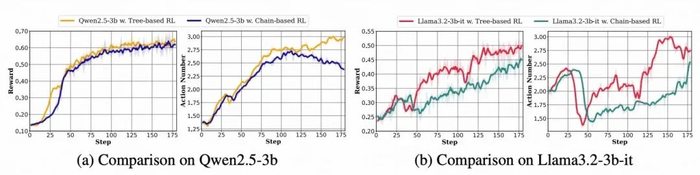
除了性能上的提升,团队还发现 Tree-based 方法能够激发模型学习到更多轮的交互次数,这对于更加复杂的 Agent 任务有重要意义。
总结与未来展望
团队提出的 Tree-GRPO 算法给 Agentic RL 带来了全新思路,解决了现有方法中 rollout 预算大、监督信号稀疏的两大问题。通过树结构的采样和优势估计方法,Tree-GRPO 能够在多轮 Agent 任务中实现更高效、稳定的 RL 训练。
团队表示,树搜索方法是一种探索与利用的权衡,如何动态地调整 RL 训练中彼此的权重是优化学习效果的重要因素。